Instrukcja korzystania z API do danych statystycznych Eurostatu
Eurostat oferuje dostęp do całego zasobu danych ze swoich baz danych przez usługi sieciowe (API) w trzech formatach (SDMX, Json i Unicode):
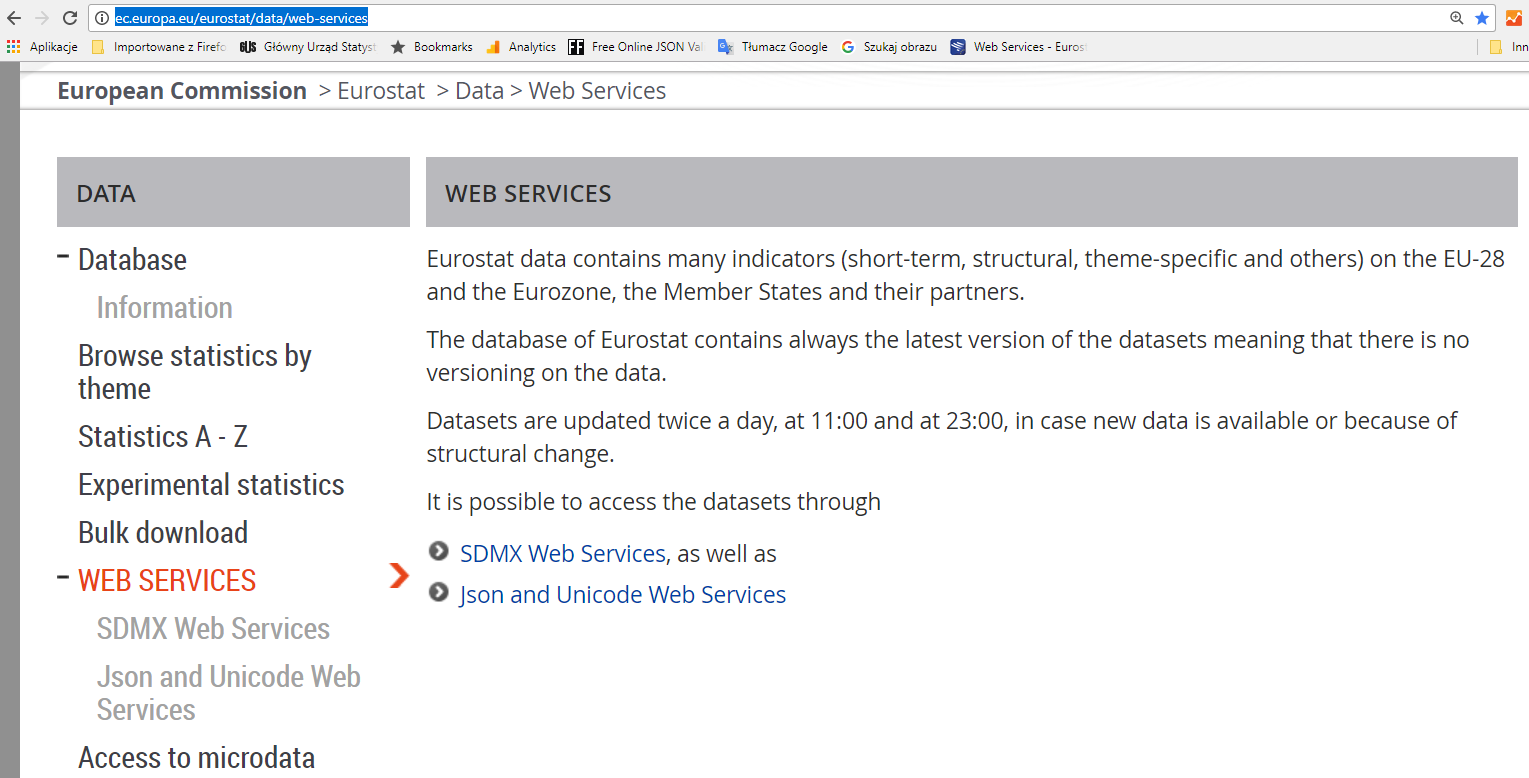
SDMX (Statistical Data and Metadata Exchange) – to międzynarodowy standard wymiany dany statystycznych wraz z metadanymi (opisami, uwagami itp.). W podstawowej wersji SDMX-ML wykorzystuje format XML.
Oferuje duże możliwości, ale nie jest powszechnie znany poza statystyką i wymaga czasu na naukę. Polecany jedynie dla pasjonatów lub osób, które są lub chcą być związane zawodowo ze statystyką lub planują zajmować się analizą zbiorów danych statystycznych.
Na potrzeby hackathonu polecamy prostszy interfejs dostępu do danych zwracający dane w formacie JSON-stat:
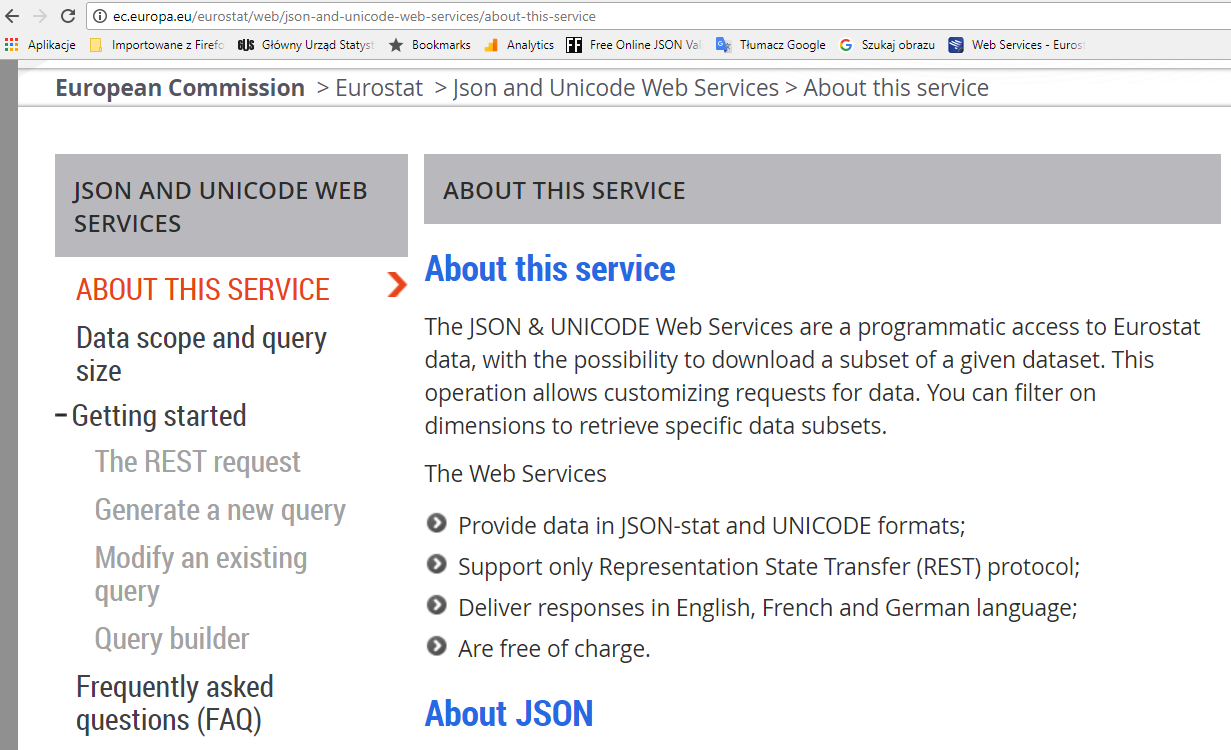
Instrukcja krok po kroku
A. Jak wybrać dane
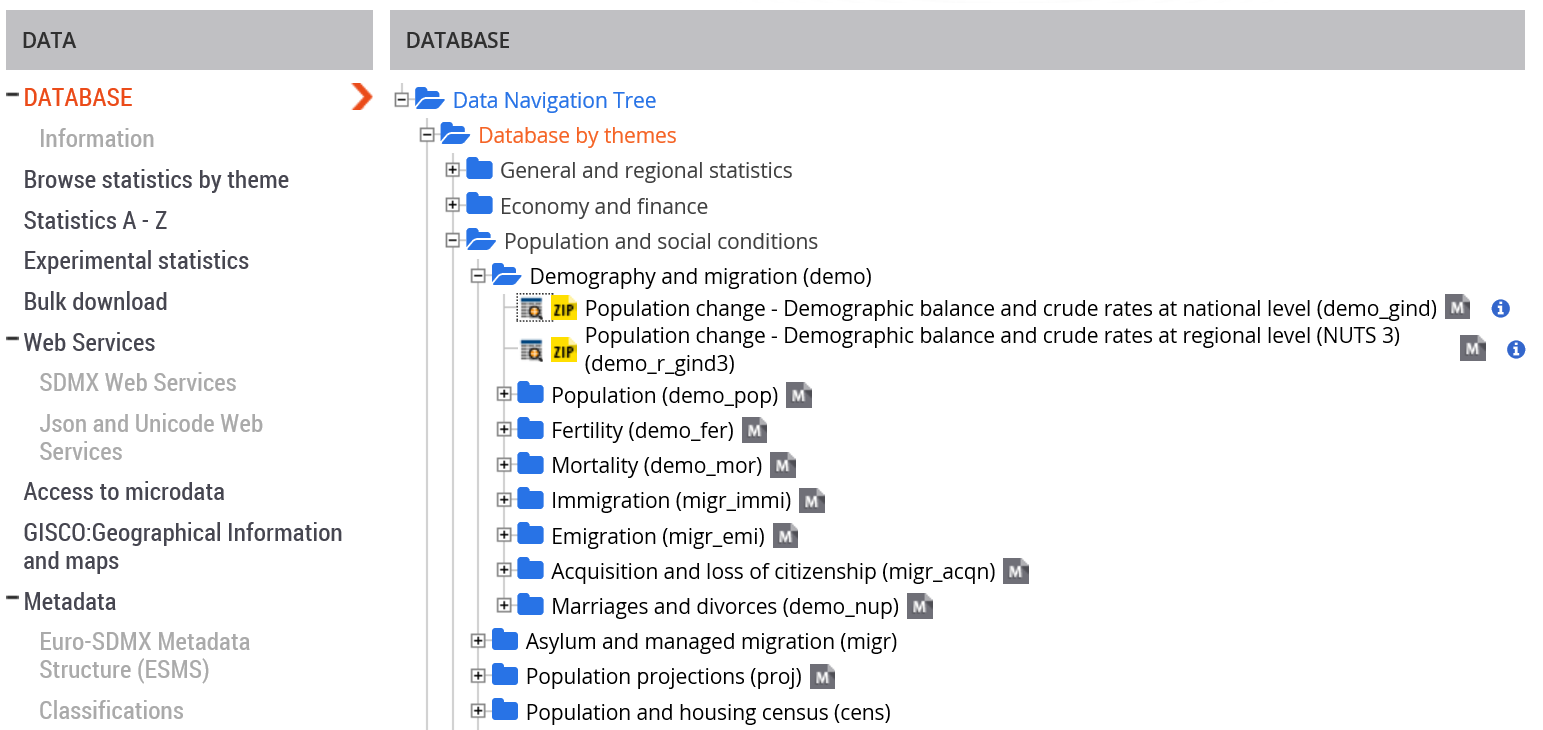
- będziemy potrzebować kodu zbioru danych, który pobieramy ze strony z bazami Eurostatu
2. kopiujemy wybrany kod i wklejamy do Query Buildera i klikamy Next:
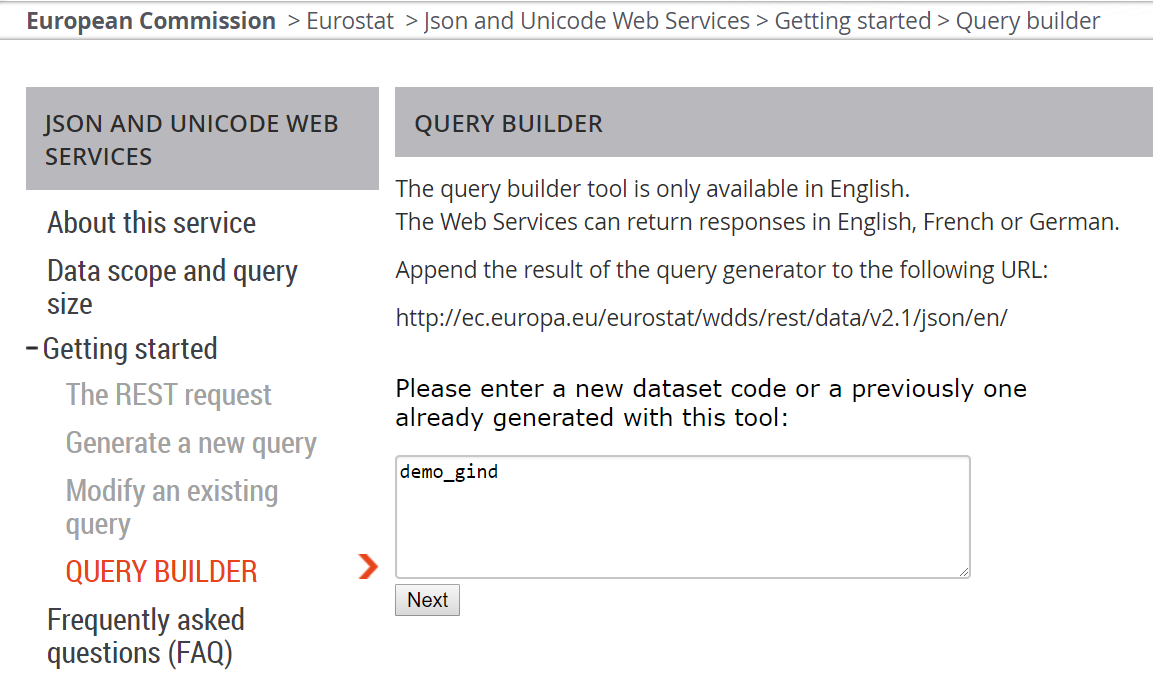
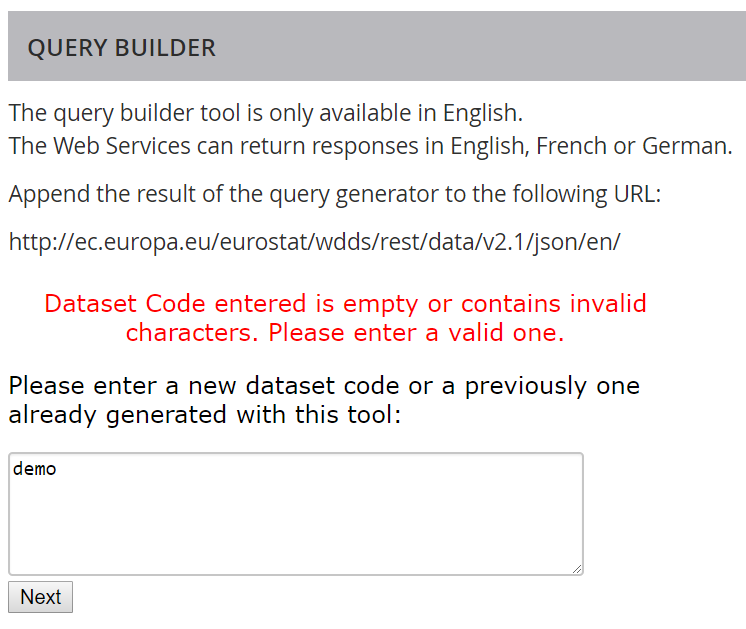
Ważne, aby korzystać z kodu zbioru danych (z najniższego poziomu drzewa), a nie kodu dziedziny
np. zadziała nam demo_gind,
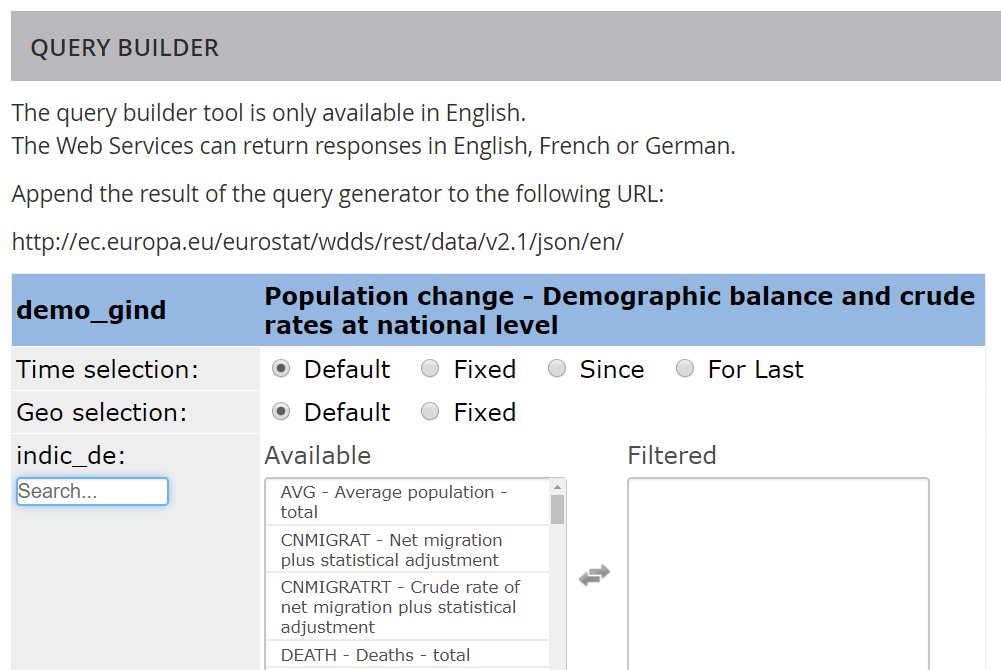
a nie zadziała samo demo:
3. Wybieramy za jaki okres mają być pobrane dane (polecamy dynamiczne określenie okresu np. dla ostatnich dostępnych 3 lat, kwartałów lub miesięcy lub od np. 2010 roku – zapewni to automatyczną aktualizację danych dla tworzonej aplikacji).
Opcje w Time selection oznaczają:
Default – wszystkie dostępne okresy odniesienia w bazie (UWAGA w zależności od wskaźnika danych może być dość dużo i na początku prawidłowa interpretacja odpowiedzi serwera może być trudna)
Fixed – umożliwia swobodny wybór okresów odniesienia, ale tylko spośród już dostępnych (brak możliwości automatycznej aktualizacji)
Since – wszystkie dostępne dane od wskazanego okresu np. od 2010 roku. Gdy pojawią się nowe dane w bazie, to dostaniemy dłuższy szereg. Opcja zapewnia automatyczną aktualizację danych, ale trzeba przewidzieć i zapewnić prawidłowe wyświetlanie coraz dłuższego szeregu danych w tworzonej aplikacji.
For Last – określona liczba kolejnych okresów odniesienia od najnowszych dostępnych. Opcja zapewnia automatyczną aktualizację danych i otrzymujemy zawsze szereg danych o stałej długości.
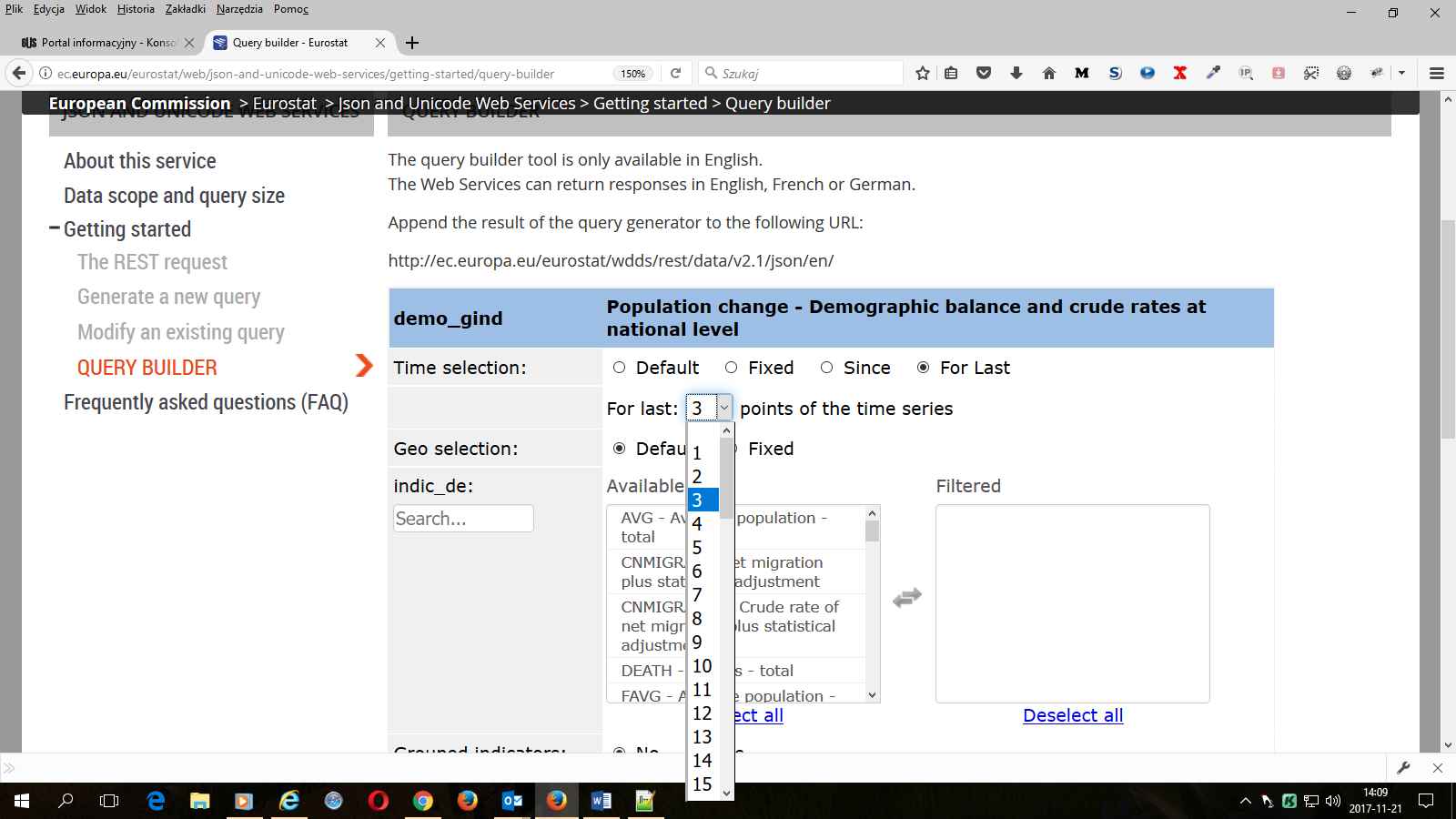
Uwaga: Może się zdarzyć, że 3 ostatnie dostępne lata obejmą rok, dla którego utworzono już odpowiednią kolumnę w bazie danych, ale jeszcze nie wprowadzono danych. Wtedy w pliku wynikowym zamiast wartości dla danego roku dostaniemy dwukropki " : " oznaczające brak danych. Jest to sytuacja przejściowa – dane wkrótce zostaną uzupełnione, ale tworząc aplikację trzeba uwzględnić taką możliwość.
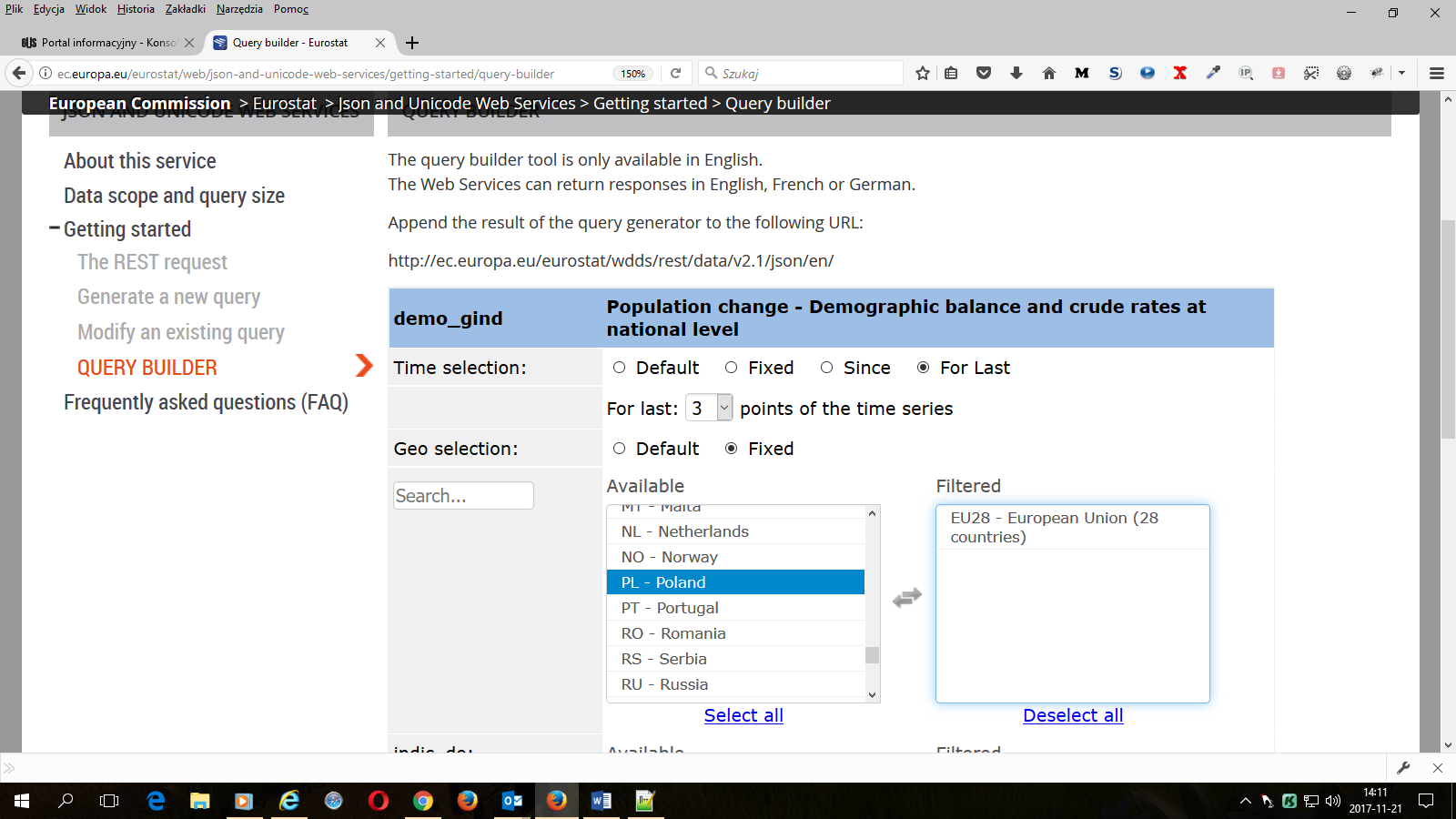
4. Wybieramy kraje i inne obniesienia geograficzne (grupy krajów np. państwa należące do Unii Europejskiej lub regiony)
Opcje w Geo selection oznaczają:
Default – wszystkie dostępne w bazie (UWAGA w zależności od wskaźnika danych może być dość dużo i na początku prawidłowa interpretacja odpowiedzi serwera może być trudna)
Fixed – umożliwia swobodny wybór krajów lub regionów – polecamy na początek wybrać tylko kilka krajów
5. Wybieramy wskaźniki, czyli rodzaje informacji statystycznej dostępnej w danym zbiorze danych np. liczbę ludności wg stanu z dania 1 stycznia danego roku:
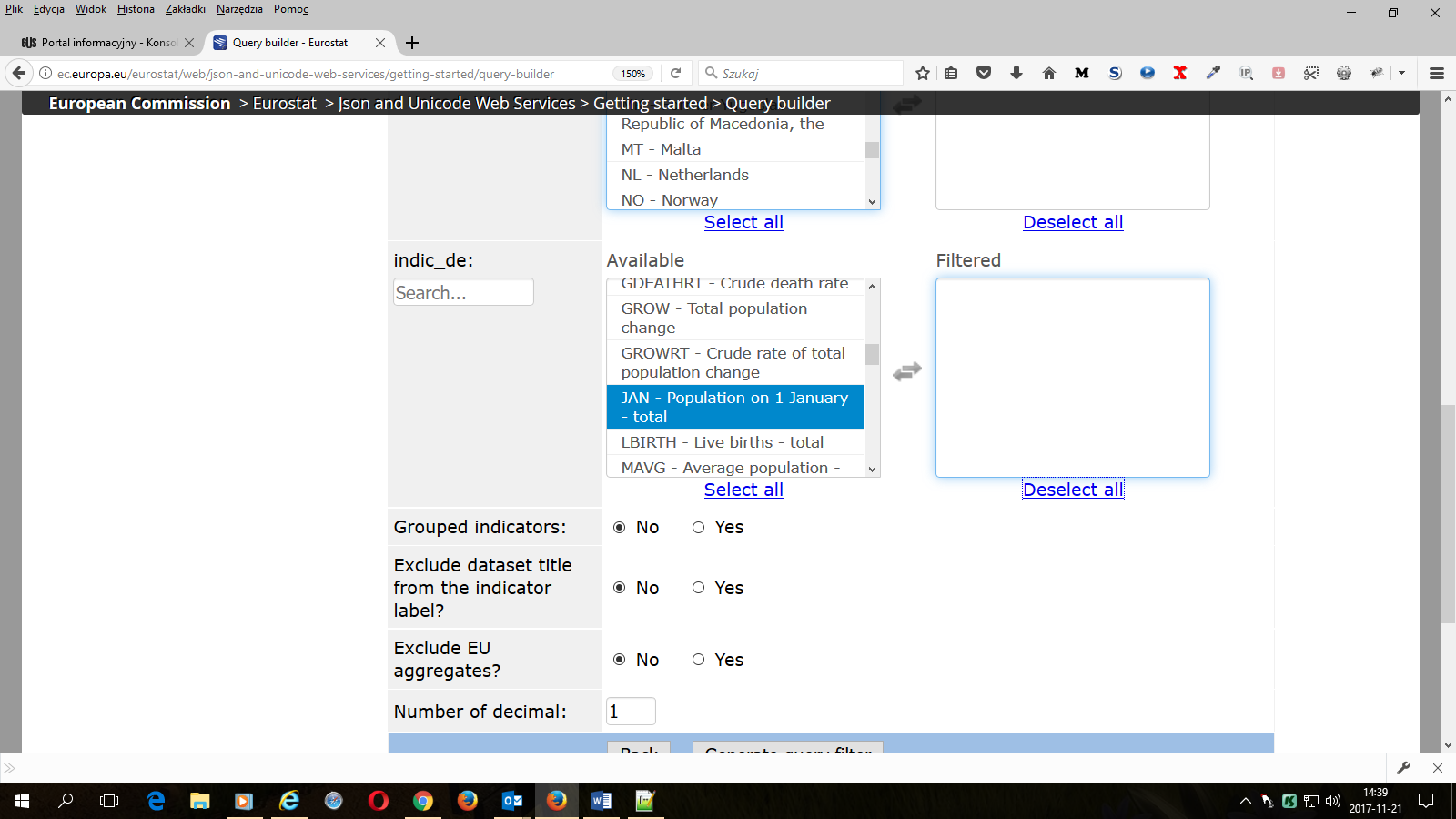
6. Decydujemy, czy chcemy mieć w naszym pliku wynikowym:
- Pogrupowane wskaźniki
- Wyłączyć nazwę zbioru danych w opisie wskaźnika
- Dane dla Unii Europejskiej i strefy Euro
Domyślnie wszystkie te opcje ustawione są na „nie” i zwykle może tak zostać.
7. Wybieramy z jaką dokładnością do miejsca po przecinku mają być podane dane – domyślnie jest jedno miejsce po przecinku i zwykle to wystarczy. UWAGA Jeśli dane składają się wyłącznie z liczb całkowitych (jak w naszym przypadku z liczbą ludności) niezależnie od tego jaką precyzję wybierzemy i tak dostaniemy wynik w postaci liczb całkowitych.
8. Klikamy przycisk Generate query filter i otrzymujemy zestaw parametrów do wklejenia do naszego zapytania do serwera Eurostatu.
UWAGA – jeśli widzimy pustą, białą stronę, to trzeba ją przewinąć do góry – powinniśmy zobaczyć takie okno z parametrami do naszego zapytania:
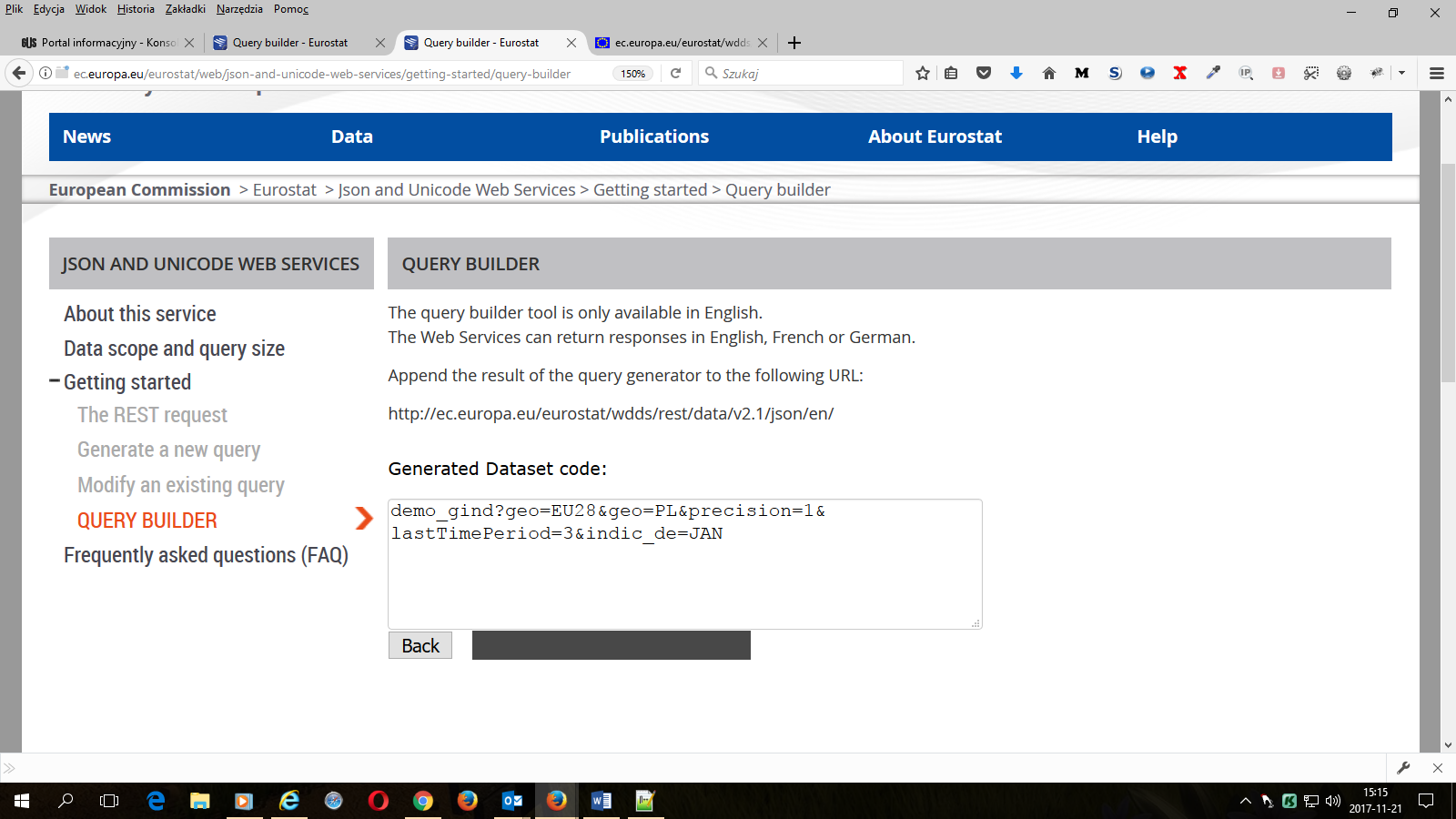
Kopiujemy tekst z okna: demo_gind?geo=EU28&geo=PL&precision=1&lastTimePeriod=3&indic_de=JAN
Nasz filtr składa się z kodu zbioru danych i kolejnych parametrów dołączanych po znaku ? i łączonych znakiem &.
B. Jak wygenerować link z zapytaniem do serwera i pobrać plik z danymi
1. Początek linku jest zawsze taki sam: http://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/
2. Doklejamy do niego filtr wygenerowany w poprzednim kroku: http://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/demo_gind?geo=EU28&geo=PL&precision=1&lastTimePeriod=3&indic_de=JAN
3. Testujemy działanie naszego linku – klikamy i przechodzimy do podanej strony (przeglądarka Firefox pokoloruje nam składnię i pokaże nam dane w bardziej czytelny sposób):
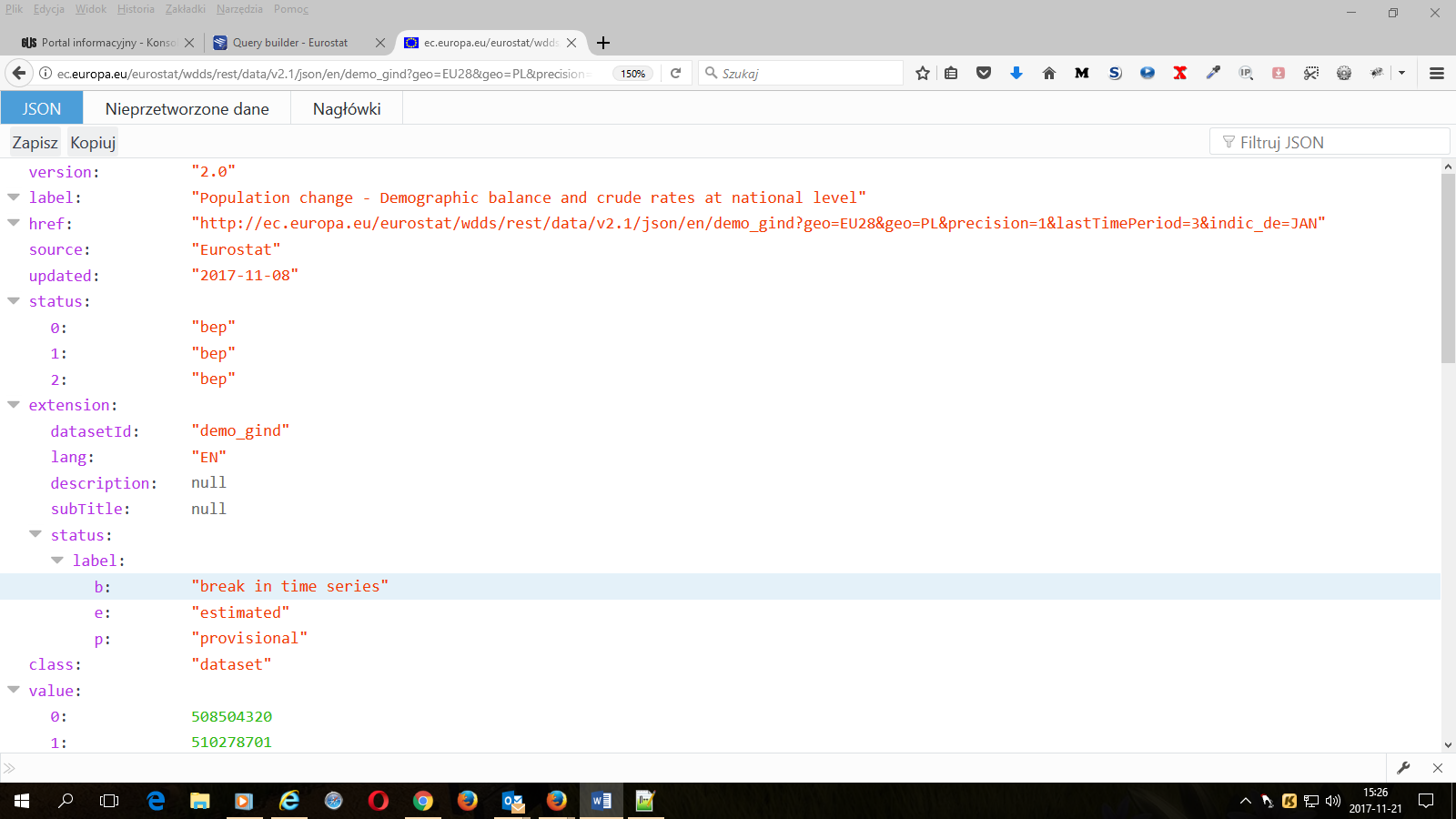
Link działa poprawnie, serwer Eurostatu zwraca żądane dane w formacie Json. Można wykorzystać usługę sieciową działającą pod podanym adresem do pobierania danych do tworzonej aplikacji. Aby jednak sensownie ich użyć programista musi umieć je poprawnie zinterpretować i o tym będzie następna część instrukcji.
C. Jak interpretować odpowiedź serwera
1. version : "2.0"
to wersja usługi sieciowej Eurostatu (niestety, jak się zmieni wersja (np. na 3.0), to może pojawić się problem z pobieraniem danych. Przy zmianie np. z 2.0 na 2.1 nie powinno być problemów.)
2. label : "Population change - Demographic balance and crude rates at national level"
to nazwa zbioru danych z których korzystamy (o nazwie kodowej demo_gind) – UWAGA zbiór danych zwykle zawiera wiele wskaźników, a w tym przykładzie wybraliśmy tylko jeden, więc to nie jest dobra nazwa dla naszego zestawu danych zapisanego w pliku Json. W naszym przypadku to nazwa obiektu nadrzędnego.
oczywiste - to link do zbioru danych, podobnie nie wymagają komentarza kolejne dwie linie:
4. source : "Eurostat"
5. updated : "2017-11-08"
6. status :
0 : "bep"
1 : "bep"
2 : "bep"
To są kody (skróty) uwag metodologicznych (notek). Opisy notek są podane dalej, w sekcji extension :
status :
label :
b : "break in time series"
e : "estimated"
p : "provisional"
Wiemy więc, że dla pierwszych trzech wartości (czyli jak się dalej przekonamy dla danych dla UE) są przerwy w szeregu czasowym (dla tych wskaźników demograficznych bardzo długim, bo sięgającym lat 60. XX wieku) i że są to dane szacunkowe oraz wstępne.
Ponieważ w naszym zestawie mamy dane tylko dla lat 2015-2017, gdzie nie ma przerw w szeregu czasowym, więc ta pierwsza informacja jest nieistotna. Dobrze jednak wiedzieć, że są to dane szacunkowe i wstępne, czyli, że mogą się zmienić.
Dobrą praktyką jest poinformowanie użytkowników tworzonej aplikacji o wszelkich notkach dotyczących pokazywanych im danych, ale można to zrobić na dwa sposoby:
- albo wyświetlać własne opisy na podstawie notek Eurostatu – wtedy jednak programista sam musi decydować, które notki są istotne (bo gdy pokazuje krótki, ale pełny szereg czasowy i „automatycznie” zamieści notkę, że w szeregu czasowym są przerwy, to tylko wprowadzi użytkowników w błąd)
- albo pod wykresem, mapką lub inną wizualizacją danych umieścić link źródło danych prowadzący do tabeli z danymi (tej z której pobraliśmy kod zbioru danych w kroku pierwszym). Wtedy odpowiedzialność za opisanie metodologii uzyskania pokazywanych danych przejmuje dostawca, czyli Eurostat. Na potrzeby hackathonu polecamy to drugie rozwiązanie.
7. extension :
datasetId : "demo_gind"
lang : "EN"
description : null
subtitle : null
status :
label :
b : "break in time series"
e : "estimated"
p : "provisional"
Ta część zawiera dodatkowe opis i informacje dotyczące naszych danych. Opisy statusu zostały omówione powyżej, a pozostałe elementy (kod zbioru danych, język) nie wymagają komentarza.
8. class : "dataset"
Informacja, że otrzymaliśmy obiekt klasy „Zbiór danych”.
9. value :
0 : 508504320
1 : 510278701
2 : 511805088
3 : 38005614
4 : 37967209
5 : 37972964
To zawartość poszczególnych komórek, ale jeszcze nie wiemy jaką strukturę danych należy do nich zastosować. O tym będzie w następnym punkcie.
10. dimension :
indic_de :
label : "indic_de"
category :
index :
JAN : 0
label :
JAN : "Population on 1 January - total "
geo :
label : "geo"
category :
index :
EU28 : 0
PL : 1
label :
EU28 : "European Union (28 countries)"
PL : "Poland"
time :
label : "time"
category :
index :
2015 : 0
2016 : 1
2017 : 2
label :
2015 : "2015"
2016 : "2016"
2017 : "2017"
Mamy trzy wymiary: wskaźnik, obszar geograficzny i czas.
Ogólnie strukturą danych zbioru danych z bazy Eurostatu jest więc kostka wielowymiarowa (oprócz powyższych trzech wymiarów, mających zastosowanie do wszystkich wskaźników, mogą być jeszcze dalsze podziały np. na płeć).
Przygotowując sobie kontener na dane można użyć tablicy wielowymiarowej o rozmiarze podanym w punkcie 11 (size :), lub bardziej uniwersalnej wielowymiarowej ArrayListy.
W naszym przykładzie mamy tylko jeden wskaźnik, więc struktura danych to tabela dwuwymiarowa:
|
geo \ time |
0 |
1 |
2 |
|
0 |
|||
|
1 |
Uzupełniając ją o kody i opisy już w języku polskim otrzymamy:
|
time |
0 |
1 |
2 |
||
|
kod |
2015 |
2016 |
2017 |
||
|
geo |
kod |
opis |
2015 |
2016 |
2017 |
|
0 |
EU28 |
Unia Europejska |
|||
|
1 |
PL |
Polska |
|||
Wartości z punktu 8 wstawiamy kolejno w komórki (wg numerów / indeksów):
|
time |
0 |
1 |
2 |
||
|
kod |
2015 |
2016 |
2017 |
||
|
geo |
kod |
opis |
2015 |
2016 |
2017 |
|
0 |
EU28 |
Unia Europejska |
0 |
1 |
2 |
|
1 |
PL |
Polska |
3 |
4 |
5 |
Podstawiając w miejsce numerów wartości otrzymamy:
|
time |
0 |
1 |
2 |
||
|
kod |
2015 |
2016 |
2017 |
||
|
geo |
kod |
opis |
2015 |
2016 |
2017 |
|
0 |
EU28 |
Unia Europejska |
508504320 |
510278701 |
511805088 |
|
1 |
PL |
Polska |
38005614 |
37967209 |
37972964 |
Nazwą naszej tabeli jest nazwa wskaźnika:
label :
JAN : "Population on 1 January - total "
Po polsku: Liczba ludności ogółem wg stanu z 1 stycznia danego roku.
Tabela sformatowana w sposób czytelny dla ludzi powinna więc wyglądać tak:
Liczba ludności ogółem wg stanu z 1 stycznia danego roku
|
2015 |
2016 |
2017 |
|
|
Unia Europejska |
508 504 320 |
510 278 701 |
511 805 088 |
|
Polska |
38 005 614 |
37 967 209 |
37 972 964 |
Jeżeli dla ostatniego roku otrzymaliśmy same dwukropki " : " zamiast wartości, to znaczy, że Eurostat dodał już kolumnę z najnowszym rokiem do bazy danych, ale nie wypełnił jej jeszcze wartościami. Dane wkrótce się pojawią, ale trzeba przygotować aplikacje na możliwy drak danych oraz poinformować użytkowników co się stało i dlaczego zamiast spodziewanych np. 3 lat na wykresie lub innej wizualizacji widzą tylko dwa lata.
11. id :
0 : "indic_de"
1 : "geo"
2 : "time"
To kody poszczególnych wymiarów.
12. size :
0 : 1
1 : 2
2 : 3
To rozmiary naszej kostki wielowymiarowej.
Możemy łatwo obliczyć ile danych otrzymamy: 1 x 2 x 3 = 6 wartości.
Jeśli wyślemy nie sparametryzowane zapytanie do serwera Eurostatu o dane z tego samego kodu:
http://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/demo_gind
to otrzymamy:
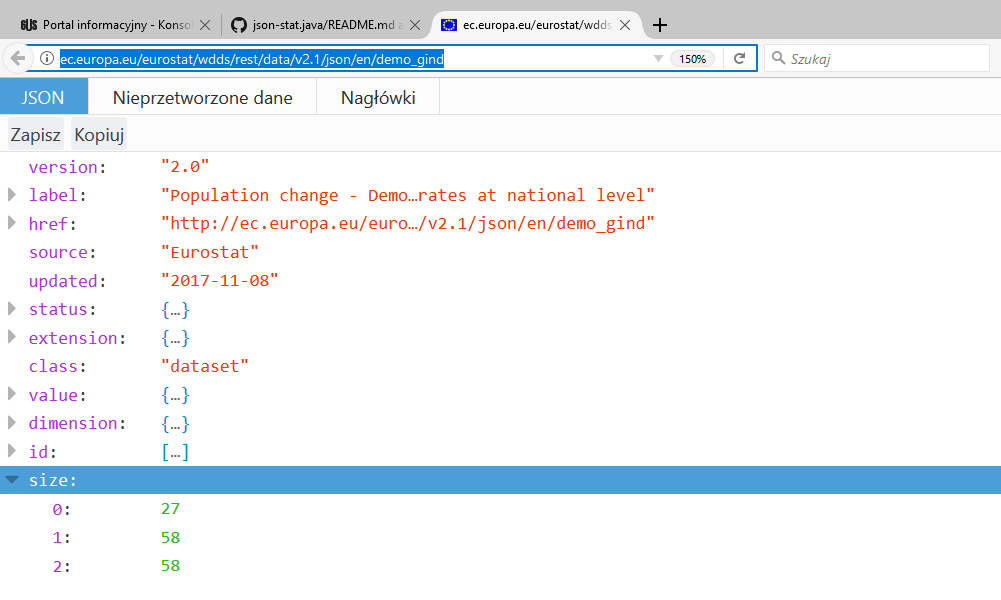
Rozmiary wynikowej kostki to 27 wskaźników x 58 krajów x 58 lat = 90828 wartości. Nie jest to naprawdę duży zbiór danych, ale osobom bez przygotowania praca z nim może sprawić trudność. Oczywiście taka ilość danych jest też zupełnie niepraktyczna do pokazywania użytkownikom – trzeba je już sprytnie filtrować przed wizualizacją.
Unicode
Jeśli zamiast danych w formacie Json preferujesz dane w formacie Unicode, to wystarczy zamienić w naszym przykładowym linku słowo json na unicode:
Odpowiedź serwera jest czytelniejsza dla człowieka, niż w przypadku nieprzetworzonych danych Json:
META CODE Name Population change - Demographic balance and crude rates at national level, Population on 1 January - total Population change - Demographic balance and crude rates at national level, Population on 1 January - total Population change - Demographic balance and crude rates at national level, Population on 1 January - total ID demo_gindJAN demo_gindJAN demo_gindJAN DESCRIPTION Code: demo_gind<br/>Data last updated on: 08.11.2017 Code: demo_gind<br/>Data last updated on: 08.11.2017 Code: demo_gind<br/>Data last updated on: 08.11.2017 UNIT FLAGS b=break in time series;e=estimated;p=provisional b=break in time series;e=estimated;p=provisional b=break in time series;e=estimated;p=provisional PARSETYPE S S F F F PRECISION 1 1 1 SLICE NA NA 2015 2016 2017 EU28 European Union (28 countries) 508504320(b,e,p) 510278701(b,e,p) 511805088(b,e,p) PL Poland 38005614 37967209 37972964
Metadane, kod i nazwa zbioru danych jest taka sama i składa się z nazwy zbioru danych Eurostatu i nazwy wskaźnika.
Identyfikator (połączone kody zbioru danych i wskaźnika), opis (kod zbioru danych i data modyfikacji) oraz flagi (notki) z jakiegoś powodu są powtórzone trzy razy (dla każdego wiersza w tabeli osobno).
Nie podano jednostek – pole Unit jest puste. Wiemy jednak, że wartości w tabeli dotyczą liczby ludności, więc jednostkami miary w tym przypadku są osoby. Być może gdyby podawano dane w tysiącach lub milionach osób w tym miejscu pojawiłaby się odpowiednia informacja.
Podany typ danych (PARSETYPE) w kolejnych kolumnach tabeli – S to String, F – Float. Niestety nie uwzględniono kodów notek dołączonych do wartości liczbowych np. 508504320(b,e,p),więc konwertowanie takiego ciągu znaków na liczbę zmiennoprzecinkową zakończy się błędem. Trzeba najpierw oddzielić notki.
Liczba miejsc po przecinku jest taka jaką podaliśmy z zapytaniu. UWAGA Nie dotyczy to rodzaju liczby zmiennoprzecinkowej (float single precision). Jeśli dane składają się wyłącznie z liczb całkowitych (jak w naszym przypadku z liczbą ludności) niezależnie od tego jaką precyzję wybierzemy i tak dostaniemy wynik w postaci liczb całkowitych.
Tabela z danymi (wybrany przekrój z kostki trójwymiarowej) składa się z trzech wierszy, z których pierwszy zawiera nazwy kolumn, z wyjątkiem dwóch pierwszych pozycji oznaczonych NA (not applicable).